Architecture Canonique, Conception d'URL, Logique de Résolution, Spécification d'API et d'Évolutivité
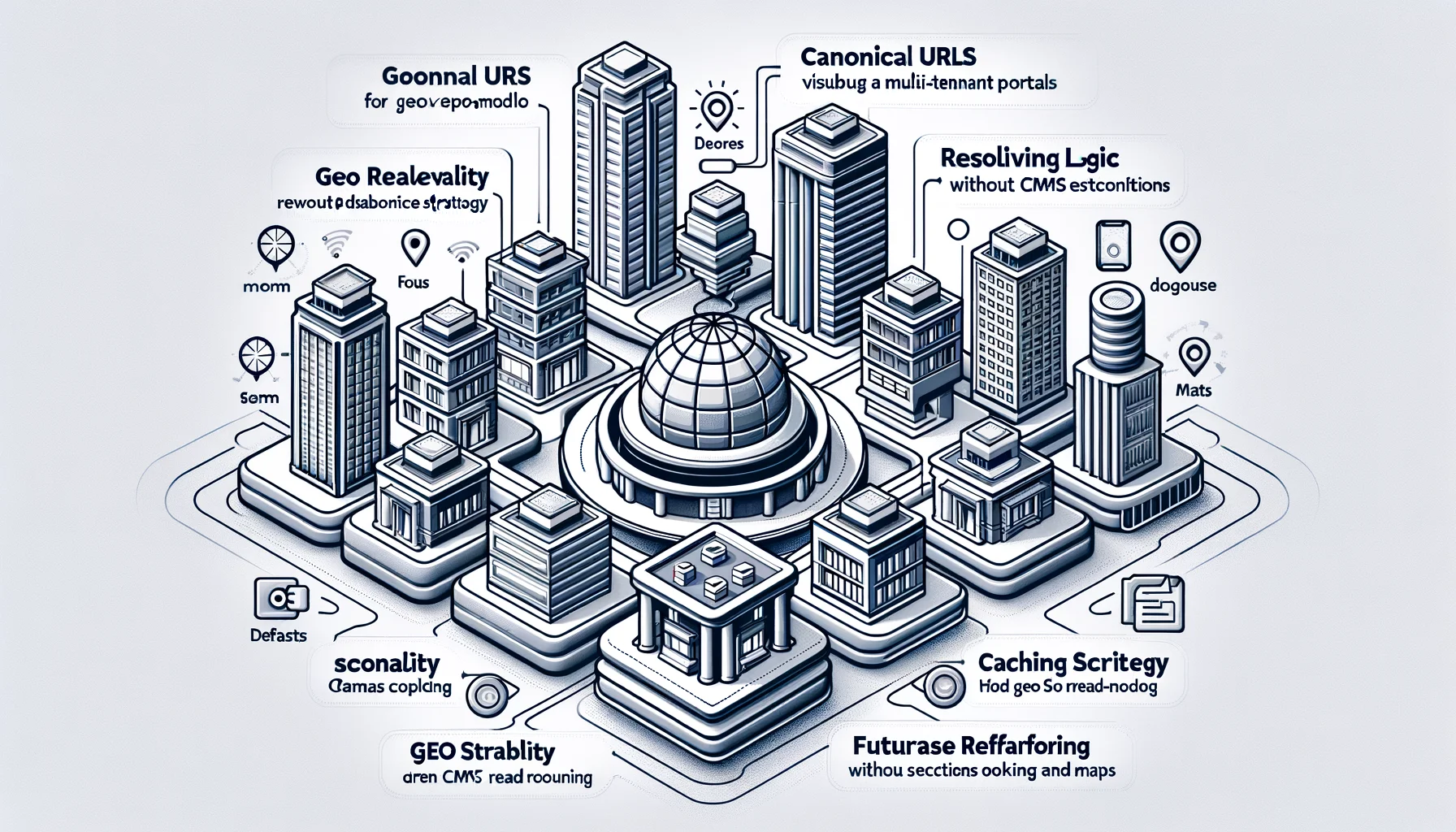
Geo Discovery : architecture canonique, conception des URL, logique du resolver, API et spécification de scalabilité
Ce document spécifie la surface de découverte géographique (pays/ville/rayon) à travers plusieurs portails (multi-tenant), sans forcer un refactoring immédiat de la base de données et sans couplage avec le routage du CMS (page/article). Il maintient une SEO stable, reste compatible avec le cache et laisse de la place pour la réservation, les avis et les cartes sans transformer l’application en un bloc monolithique.
Contraintes et non-objectifs
- Multi-tenant : la même base de code dessert plusieurs portails. Le tenant influence la portée du contenu, l’identité visuelle et parfois la source de données.
- La découverte géographique doit supporter : pays, ville et recherche par rayon (autour d’un point).
- Aucun refactoring immédiat de la base de données : nous ne pouvons pas restructurer les tables existantes en un schéma geo idéal à ce stade.
- Indépendance vis-à-vis du routage CMS : les pages geo ne sont ni des « posts » ni des « pages ». Elles ne peuvent pas être bloquées par des conflits de slug CMS.
- Stabilité SEO : les URL canoniques ne doivent pas changer lorsque les filtres ou les options de tri changent.
- Compatibilité cache : le CDN et le cache serveur doivent avoir des clés prévisibles. Éviter toute variation par utilisateur.
- Séparation stricte des responsabilités : discovery, CMS et résolution du tenant sont des modules distincts avec des frontières explicites.
- Non-objectif (pour l’instant) : géocodage parfait. Nous acceptons un seul géocodeur, une stratégie de normalisation unique et stockons le résultat normalisé.
Architecture canonique
Nous implémentons la découverte géographique comme un bounded context autonome avec une surface publique minimale : (1) URL → Resolver, (2) Resolver → Query Plan, (3) Query Plan → Data Providers, (4) Réponse → métadonnées SEO et cache. Les routes CMS n’appellent jamais la discovery. La discovery n’appelle jamais le routage CMS. Elles ne partagent que des utilitaires bas niveau (HTTP, cache, contexte tenant).
Composants clés
- TenantContext : résout le tenant à partir de l’en-tête Host (ou d’un identifiant de portail explicite pour les appels internes).
- GeoResolver : analyse et valide les segments d’URL géographiques ; émet un GeoQuery normalisé.
- GeoIndex (Read Model) : table ou collection séparée qui mappe entityId → lat/lng + scope tenant + champs minimaux recherchables. Cela évite le refactoring des tables de la base source.
- Data Providers : sources interchangeables (par exemple tables SQL existantes, API WordPress, autre service de portail). Elles sont encapsulées derrière une interface.
- SEO Router : produit l’URL canonique et les métadonnées (canonical, hreflang si nécessaire, indicateurs robots).
- Couche de cache : clés de cache CDN et cache côté serveur avec clés tenant-scopées et versionnement.
Structure des dossiers
apps/
web/
routes/
discovery/ # discovery entry points (not CMS)
pages/
[...cms].vue # CMS catch-all (kept away from /discover)
server/
src/
tenant/
TenantContext.ts
tenantConfig.ts
discovery/
geo/
GeoResolver.ts
GeoQuery.ts
GeoCanonical.ts
GeoController.ts
providers/
GeoProvider.ts
SqlGeoProvider.ts
RemoteGeoProvider.ts
index/
GeoIndexRepository.ts
migrations/
cache/
Cache.ts
cacheKeys.ts
http/
errors.ts
requestContext.ts
packages/
shared/
src/
geo/
normalize.ts
haversine.ts
validation/
zod.ts
Conception des URL (SEO Canonical)
Nous conservons l’URL canonique strictement hiérarchique et lisible par l’humain. Les filtres et le tri restent dans la querystring mais n’affectent PAS le canonical. La recherche par rayon utilise une page « near » stable avec un canonical basé sur une cellule de coordonnées arrondie, et non sur les lat/lng bruts. Cela empêche la génération infinie de variantes d’URL et évite l’explosion du cache. C’est un compromis délibéré.
- Landing pays : /discover/{countryCode} (exemple : /discover/de)
- Landing ville : /discover/{countryCode}/{citySlug} (exemple : /discover/de/munich)
- Near (rayon) : /discover/{countryCode}/near/{cellId} (exemple : /discover/de/near/u281z) où cellId est un identifiant court de type geohash
- Paramètres de requête optionnels (non canoniques) : ?q=shih-tzu&category=pet-care&sort=rating&page=2
- Le tenant n’est PAS dans le chemin. Le tenant est déterminé par l’hôte (portal-a.tld, portal-b.tld). Les appels internes transmettent x-tenant-id.
Règles de canonicalisation
- Les pages pays/ville canonisent vers leur propre chemin propre (sans querystring).
- Les pages near canonisent vers /discover/{country}/near/{cellId}. Le canonical est dérivé d’une cellule arrondie, pas des coordonnées entrantes.
- page=1 est omis du canonical et de la génération des liens internes.
- Les combinaisons non supportées (par ex. incohérence de pays) retournent un 404, pas une redirection. Les chaînes de redirection nuisaient au budget de crawl lors des tests.
Logique du resolver
L’entrée du resolver est (tenant, pathname, query). La sortie est un GeoQuery normalisé avec un query plan. Aucun accès à la base de données dans le resolver. Cette séparation a été cruciale plus tard : elle nous a évité un bug de cache particulièrement pénible.
export type TenantId = string;
export type GeoScope =
| { kind: 'country'; countryCode: string }
| { kind: 'city'; countryCode: string; citySlug: string }
| { kind: 'near'; countryCode: string; cellId: string; radiusMeters: number };
export type GeoFilters = {
q?: string;
category?: string;
sort?: 'relevance' | 'rating' | 'distance';
page: number;
pageSize: number;
};
export type GeoQuery = {
tenantId: TenantId;
scope: GeoScope;
filters: GeoFilters;
canonicalPath: string;
cacheKey: string;
};
import { z } from 'zod';
import type { GeoQuery, TenantId } from './GeoQuery';
const QuerySchema = z.object({
q: z.string().trim().min(1).max(120).optional(),
category: z.string().trim().min(1).max(60).optional(),
sort: z.enum(['relevance', 'rating', 'distance']).optional(),
page: z.coerce.number().int().min(1).max(200).default(1),
pageSize: z.coerce.number().int().min(5).max(50).default(20)
});
const CountryCodeSchema = z.string().regex(/^[a-z]{2}$/i);
const CitySlugSchema = z.string().regex(/^[a-z0-9-]{2,80}$/i);
const CellIdSchema = z.string().regex(/^[a-z0-9]{4,12}$/i);
export function resolveGeo(
tenantId: TenantId,
pathname: string,
query: Record<string, unknown>
): GeoQuery {
const filters = QuerySchema.parse(query);
const parts = pathname.split('/').filter(Boolean);
if (parts[0] !== 'discover') {
throw new Error('Not a discovery route');
}
const countryCode = CountryCodeSchema.parse(parts[1] ?? '');
let scope: GeoQuery['scope'];
if (parts.length === 2) {
scope = { kind: 'country', countryCode: countryCode.toLowerCase() };
} else if (parts[2] === 'near') {
const cellId = CellIdSchema.parse(parts[3] ?? '');
const radiusMeters = Math.min(50000, Math.max(500, Number(query['r'] ?? 5000)));
scope = { kind: 'near', countryCode: countryCode.toLowerCase(), cellId, radiusMeters };
} else {
const citySlug = CitySlugSchema.parse(parts[2] ?? '');
scope = { kind: 'city', countryCode: countryCode.toLowerCase(), citySlug: citySlug.toLowerCase() };
}
const canonicalPath = canonicalizePath(scope);
const cacheKey = buildCacheKey(tenantId, scope, filters);
return {
tenantId,
scope,
filters: { ...filters, sort: filters.sort ?? 'relevance' },
canonicalPath,
cacheKey
};
}
function canonicalizePath(scope: GeoQuery['scope']): string {
switch (scope.kind) {
case 'country': return `/discover/${scope.countryCode}`;
case 'city': return `/discover/${scope.countryCode}/${scope.citySlug}`;
case 'near': return `/discover/${scope.countryCode}/near/${scope.cellId}`;
}
}
function buildCacheKey(
tenantId: string,
scope: GeoQuery['scope'],
filters: { q?: string; category?: string; sort?: string; page: number; pageSize: number }
): string {
const q = filters.q ? `q=${filters.q}` : '';
const c = filters.category ? `cat=${filters.category}` : '';
const s = `sort=${filters.sort ?? 'relevance'}`;
const p = `p=${filters.page}`;
const ps = `ps=${filters.pageSize}`;
const scopeKey =
scope.kind === 'country'
? `country:${scope.countryCode}`
: scope.kind === 'city'
? `city:${scope.countryCode}:${scope.citySlug}`
: `near:${scope.countryCode}:${scope.cellId}:r${scope.radiusMeters}`;
return `geo:v1:tenant=${tenantId}:${scopeKey}:${[q, c, s, p, ps].filter(Boolean).join('&')}`;
}
Flux de requête étape par étape
- L’Edge/CDN reçoit la requête. La clé de cache inclut l’hôte + le chemin + des paramètres de requête bornés (q, category, sort, page, pageSize, r).
- Le serveur applicatif crée le TenantContext à partir de l’en-tête Host. Aucune base de données à ce stade.
- Le GeoResolver analyse l’URL et produit un GeoQuery avec canonicalPath et cacheKey côté serveur.
- Le GeoController construit un QueryPlan et décide quels providers appeler selon la configuration du tenant et le type de scope.
- Le provider exécute une requête read-model sur le GeoIndex (rapide), puis hydrate les résultats depuis la source existante (DB SQL, API CMS) via les entity IDs.
- L’assembleur de réponse ajoute les métadonnées SEO : canonical, robots, liens de pagination.
- Le serveur définit les en-têtes de cache (s-maxage + stale-while-revalidate). Le body est tenant-scopé et n’est jamais partagé entre tenants.
Stratégie sans refactor : Read Model GeoIndex
Nous ne pouvons pas restructurer les tables de contenu existantes immédiatement. Nous ajoutons donc un GeoIndex séparé, reconstructible indépendamment. Il stocke le strict nécessaire pour une discovery efficace : tenantId, entityId, entityType, countryCode, citySlug, lat, lng et quelques champs de filtrage. L’hydratation récupère l’objet complet depuis la source actuelle.
Compromis : cohérence éventuelle. Le délai de reconstruction de l’index est acceptable pour les pages de discovery. SLA : les mises à jour apparaissent sous 15 minutes. Les besoins temps réel ultérieurs (disponibilité de réservation) constituent une surface différente et ne doivent pas réutiliser le cache de discovery.
Surface API
Deux surfaces : (A) pages HTML pour le SEO et les utilisateurs, (B) API JSON pour le rendu client et les extensions futures. Même resolver et même query plan. Présentateurs différents.
- HTML : GET /discover/{country}, /discover/{country}/{city}, /discover/{country}/near/{cellId}
- API : GET /api/discovery?scope=country|city|near&country=..&city=..&cell=..&r=..&q=..&category=..&sort=..&page=..
- Admin (interne) : POST /internal/geoindex/rebuild (protégé), POST /internal/geoindex/upsert (optionnel, ultérieurement)
import type { IncomingMessage, ServerResponse } from 'http';
import { resolveGeo } from './GeoResolver';
import { runQueryPlan } from './GeoController';
export async function discoveryApi(req: IncomingMessage, res: ServerResponse) {
const url = new URL(req.url ?? '', 'http://localhost');
const tenantId = String(req.headers['x-tenant-id'] ?? 'default');
const scope = url.searchParams.get('scope') ?? 'country';
const country = url.searchParams.get('country') ?? '';
const city = url.searchParams.get('city');
const cell = url.searchParams.get('cell');
const pseudoPath =
scope === 'city' && city
? `/discover/${country}/${city}`
: scope === 'near' && cell
? `/discover/${country}/near/${cell}`
: `/discover/${country}`;
const geoQuery = resolveGeo(tenantId, pseudoPath, Object.fromEntries(url.searchParams.entries()));
const result = await runQueryPlan(geoQuery);
res.statusCode = 200;
res.setHeader('content-type', 'application/json; charset=utf-8');
res.setHeader('cache-control', 'public, s-maxage=300, stale-while-revalidate=600');
res.end(JSON.stringify(result));
}
Scalabilité et performances
- Objectif principal de performance : servir le HTML de discovery depuis le CDN pour les landings geo populaires (pays/ville).
- Les pages near sont cacheables mais présentent davantage de variantes (cellId + r + q + category + sort + page). Nous bornons r et pageSize et validons strictement les filtres.
- La requête GeoIndex doit être rapide : index sur tenantId + countryCode + citySlug ; pour near, utiliser des buckets de cellules (match par préfixe) puis affiner par distance dans l’application.
- Éviter les calculs haversine SQL coûteux sur de grands jeux de données. Cela semble simple. Ce ne l’est pas.
- L’hydratation est batchée par liste d’entityId : une requête par entityType, pas de N+1.
Stratégie de recherche par rayon (pages near)
Nous n’exécutons pas un scan de rayon complet sur toutes les lignes. À la place : (1) le cellId mappe vers un bucket de délimitation (préfixe de type geohash), (2) récupération des candidats depuis le GeoIndex par préfixe de bucket, (3) affinage dans l’application via la distance haversine, (4) tri et pagination. Cela rend la charge DB prévisible.
export function haversineMeters(a: { lat: number; lng: number }, b: { lat: number; lng: number }): number {
const R = 6371000;
const toRad = (d: number) => (d * Math.PI) / 180;
const dLat = toRad(b.lat - a.lat);
const dLng = toRad(b.lng - a.lng);
const lat1 = toRad(a.lat);
const lat2 = toRad(b.lat);
const sinDLat = Math.sin(dLat / 2);
const sinDLng = Math.sin(dLng / 2);
const h = sinDLat * sinDLat + Math.cos(lat1) * Math.cos(lat2) * sinDLng * sinDLng;
const c = 2 * Math.asin(Math.min(1, Math.sqrt(h)));
return R * c;
}
Modèle de cache (CDN + serveur)
Nous mettons en cache à deux niveaux. Le CDN met en cache l’intégralité du HTML/JSON pour le trafic anonyme. Le cache serveur stocke les résultats des providers indexés par GeoQuery.cacheKey. La clé inclut le tenant, le scope et des filtres bornés. Tout ne doit pas être mis en cache. La disponibilité de réservation sera exclue ultérieurement.
- La clé de cache CDN varie selon l’en-tête Host : c’est la frontière tenant.
- La clé de cache serveur inclut explicitement tenantId. Ne jamais se reposer sur un host implicite en mémoire.
- TTL de cache : pays/ville 30–60 minutes au CDN (stale-while-revalidate activé). Pages near : 5 minutes.
- Nous conservons un levier manuel de purge par tenant (suffixe de version dans la clé de cache), utilisé lors des migrations et des déploiements défectueux.
Détails de stabilité SEO
- Balises canonical : pointent toujours vers le chemin hiérarchique propre (sans querystring).
- Robots : si des paramètres de requête non whitelistés sont présents (q/category/sort/page/pageSize/r), définir noindex afin de bloquer les paramètres parasites issus de liens externes.
- Pagination : rel=next/prev générés uniquement pour les pages > 1 et si resultCount > pageSize.
- Liens internes stables : l’UI émet toujours des chemins canoniques ; la querystring n’est utilisée que pour les filtres sélectionnés par l’utilisateur.
Extensions futures sans alourdissement
Nous étendons le système en ajoutant des providers et des presenters, pas en surchargeant le resolver. Les réservations, avis et cartes vivent sur des pages d’entité ou des API dédiées. La discovery reste une surface de liste et de filtrage. Cette frontière est strictement appliquée lors des revues de code.
- Réservation : endpoints /api/booking séparés. La discovery n’affiche des badges de disponibilité que s’ils sont mis en cache et non personnalisés.
- Avis : service/provider d’avis séparé. La discovery lit des champs de notation agrégés depuis le GeoIndex (pré-calculés).
- Cartes : tuiles et marqueurs récupérés via /api/discovery/markers avec un cache agressif ; ne pas intégrer dans la réponse HTML si cela dégrade le TTFB.
Un problème rencontré (et ce que nous avons changé)
Nous avons livré la première version avec une clé de cache serveur qui n’incluait PAS le tenantId. En local, cela « fonctionnait ». En staging, tout semblait correct. Puis en production : le portail A a commencé à afficher des listings du portail B sur les pages ville. Même chemin, tenant différent. Collision de cache. Moche.
La correction a été simple mais stricte : le tenantId est devenu obligatoire dans le GeoQuery et la construction de la clé de cache a été déplacée dans le resolver afin de ne pas pouvoir être omise. Nous avons aussi ajouté une assertion runtime : si des entités hydratées contiennent un tenantId différent, nous levons une erreur et sautons l’écriture en cache. Volontairement bruyant.
Query Plan et contrat des providers
import type { GeoQuery } from '../GeoQuery';
export type GeoHit = {
entityId: string;
entityType: 'place' | 'service' | 'listing';
lat: number;
lng: number;
citySlug?: string;
countryCode: string;
score?: number;
distanceMeters?: number;
};
export type GeoResult = {
hits: GeoHit[];
total: number;
page: number;
pageSize: number;
};
export interface GeoProvider {
search(query: GeoQuery): Promise<GeoResult>;
}
Le QueryPlan est un simple aiguillage basé sur la configuration du tenant et le type de scope. Par exemple : certains tenants utilisent uniquement SQL ; d’autres un service de portail distant. Même entrée GeoQuery. Même sortie GeoResult. Cela rend les déploiements prévisibles.
GeoIndex SQL : schéma minimal
CREATE TABLE geo_index (
tenant_id TEXT NOT NULL,
entity_id TEXT NOT NULL,
entity_type TEXT NOT NULL,
country_code TEXT NOT NULL,
city_slug TEXT,
lat DOUBLE PRECISION NOT NULL,
lng DOUBLE PRECISION NOT NULL,
cell_prefix TEXT NOT NULL,
category TEXT,
rating_avg DOUBLE PRECISION,
updated_at TIMESTAMP NOT NULL DEFAULT NOW(),
PRIMARY KEY (tenant_id, entity_id)
);
CREATE INDEX geo_index_country_city
ON geo_index (tenant_id, country_code, city_slug);
CREATE INDEX geo_index_cell_prefix
ON geo_index (tenant_id, country_code, cell_prefix);
Compromis (explicites)
- Nous échangeons la précision parfaite contre des URL stables : les pages near canonisent par cellId. Deux utilisateurs à 300 m peuvent atterrir sur la même page canonique. Acceptable.
- Nous échangeons la fraîcheur contre la cacheabilité : les pages de discovery ne sont pas en temps réel. Les mises à jour de l’index peuvent être différées.
- Nous évitons un refactor DB immédiat, mais payons un chemin d’écriture supplémentaire pour maintenir le GeoIndex.
- Nous évitons le couplage au routage CMS, mais possédons désormais un namespace de routes séparé (/discover). C’est intentionnel et c’est une promesse à tenir.
- Nous affinons la distance dans le code applicatif pour les recherches near afin d’éviter des calculs DB coûteux, déplaçant le CPU vers la couche applicative, plus facile à scaler horizontalement.
Plan de déploiement (pratique)
- Livrer le resolver et des pages vides retournant 404 derrière un feature flag. Vérifier que le routage n’entre pas en conflit avec le catch-all CMS.
- Construire un job de backfill GeoIndex pour un tenant. Valider les comptes par rapport aux données source. S’attendre à des écarts et les journaliser.
- Activer uniquement les pages pays. Surveiller le taux de hit cache et les statistiques de crawl.
- Activer ensuite les pages ville. Les pages near en dernier (elles génèrent des variantes).
- Une fois les clés de cache stables, ajouter des consommateurs de l’API JSON (marqueurs de carte, filtrage client).
Liste d’acceptation
- Isolation multi-tenant : un même chemin sur deux hôtes ne partage jamais des entrées de cache serveur.
- Les URL canoniques n’incluent pas de paramètres de requête et restent stables lors des changements de filtres.
- Les conflits de slug CMS n’affectent pas les routes /discover.
- Les pages near ne génèrent pas de permutations d’URL non bornées (r et pageSize limités).
- Le contrat provider retourne une pagination déterministe et des totaux cohérents.
- La reconstruction du GeoIndex peut s’exécuter sans downtime et sans verrouiller longtemps les tables source.
Related Articles
Enterprise-Grade Multi-Tenant Architecture for an International Platform
Loving Rocks is an enterprise-grade wedding platform designed with a true multi-tenant architecture, isolated databases per tenant, and built-in internationalization for global scalability, security, and long-term operational stability.
Modèle-Vue-Contrôleur (MVC) : l'épine dorsale structurelle des applications web modernes
Modèle-Vue-Contrôleur, généralement abrégé en MVC, reste l'un des modèles d'architecture les plus durables dans le développement de logiciels. Il offre aux équipes un moyen pratique de séparer la logique métier, la présentation et l'interaction utilisateur afin que les applications restent plus faciles à construire, à étendre, à tester et à maintenir. Cet article explique ce qu'est le MVC, pourquoi il est toujours important, où il s'intègre dans les piles Web d'aujourd'hui et comment il se connecte à l'architecture de plateforme plus large, à la qualité de la livraison, à la stratégie de migration et à la maturité opérationnelle.

Quectel RM500U-EA dans le ZBT Z8102AX : bandes 5G, o2 Allemagne et comportement du signal en conditions réelles
Le ZBT Z8102AX utilise un modem Quectel RM500U-EA pour la connectivité 4G et 5G. Lors du premier test pratique, le routeur s'est connecté avec succès à o2 Germany avec la bande LTE 3 et la NR n28. Le modem fonctionne, mais des diagnostics plus approfondis tels que le RSRP, le RSRQ, le SINR, le verrouillage de bande et le comportement des cellules nécessitent encore des tests appropriés.

Test du matériel et de l'emballage du ZBT Z8102AX : routeur solide, boîte fragile
Le ZBT Z8102AX fait une solide première impression en tant que routeur OpenWrt 5G fin en métal noir avec plusieurs connecteurs d'antenne, des emplacements double SIM, des ports USB, LAN/WAN et un ensemble d'accessoires pratique. Le matériel semble utile et sérieux, mais l'emballage est clairement le point faible.