Solr Fuzzy Suggester и Solr Infix Suggester через Ajax
Описание проекта
Для эффективного поиска на веб-сайте важно, чтобы пользователи быстро и легко находили соответствующие результаты. Solr Fuzzy Suggester и Solr Infix Suggester предлагают эффективное решение для этого. Их можно вызывать и фильтровать с помощью Ajax-запросов.
Suggester активируется через XML-компонент SuggestComponent в файле solrconfig.xml, как показано в следующем примере кода:
<searchComponent name="suggest" class="solr.SuggestComponent">
<lst name="suggester">
<str name="name">mySuggester</str>
<str name="lookupImpl">FuzzyLookupFactory</str>
<str name="dictionaryImpl">DocumentDictionaryFactory</str>
<str name="field">suggest_field</str>
<str name="weightField">weight</str>
<str name="suggestAnalyzerFieldType">text_general</str>
<str name="buildOnStartup">true</str>
</lst>
</searchComponent>Используя Solr Fuzzy Suggester и Solr Infix Suggester, пользователи могут быстро и легко получать релевантные результаты, поскольку они получают предложения и функции автозаполнения. Результаты запроса затем могут быть отфильтрованы, чтобы гарантировать отображение только наиболее релевантных результатов.
Внедряя эти технологии, веб-сайты могут предложить улучшенную функциональность поиска и лучший пользовательский опыт.
Пример конфигурации (Syntax Highlighter)
<searchComponent name="suggest" class="solr.SuggestComponent">
<lst name="suggester">
<str name="name">mySuggester</str>
<str name="lookupImpl">FuzzyLookupFactory</str>
<str name="dictionaryImpl">DocumentDictionaryFactory</str>
<str name="field">cat</str>
<str name="weightField">price</str>
<str name="suggestAnalyzerFieldType">string</str>
<str name="buildOnStartup">false</str>
</lst>
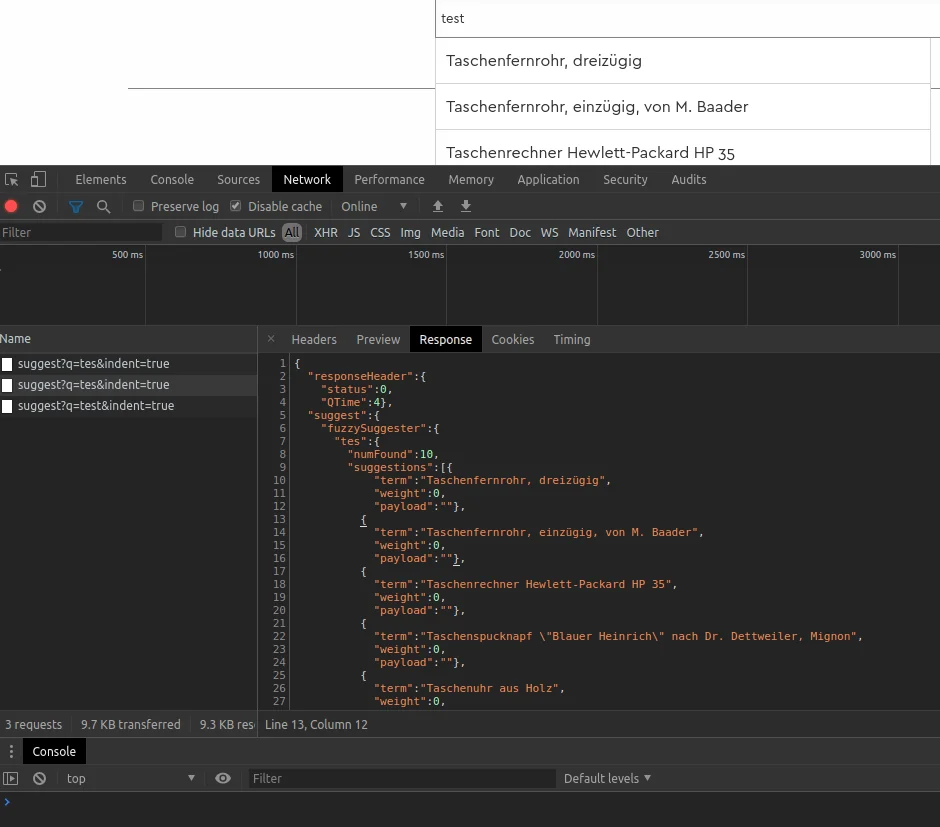
</searchComponent>Изображение показывает, что делает suggester: введенные данные не дают точного совпадения, и Solr Suggester возвращает похожие предложения. Существует несколько способов определения схожести строк. Я упомяну здесь два.
1) Fuzzy (расстояние Левенштейна)
Первая возможность — это fuzzy (нечеткий поиск), который основан на алгоритме расстояния Левенштейна.
В JavaScript это выглядело бы так:
function levenshtein(a, b) {
var t = [], u, i, j, m = a.length, n = b.length;
if (!m) { return n; }
if (!n) { return m; }
for (j = 0; j <= n; j++) { t[j] = j; }
for (i = 1; i <= m; i++) {
for (u = [i], j = 1; j <= n; j++) {
u[j] = a[i - 1] === b[j - 1] ? t[j - 1] : Math.min(t[j - 1], t[j], u[j - 1]) + 1;
} t = u;
} return u[n];
}
// a and b are strings2) Infix (сопоставление префиксов и индекс Lucene)
Вторая возможность — это infix (инфиксный поиск), который основан на сопоставлении префиксов с токенами в индексированном тексте. Он использует индекс Lucene для своего словаря. Lucene — это библиотека полнотекстового поиска (Apache Software Foundation), содержащая программные библиотеки с открытым исходным кодом.
На практике это индексированная структура, которая создает токены во время обработки. Пробелы могут обозначать конец или начало строки. Отдельные строки нормализуются для лучшего сопоставления — например, преобразование заглавных букв в строчные — а также индексируются несколько связанных вариантов из словаря.
Преимущество заключается в опциях, которые можно определить в запросе, что обеспечивает большую гибкость.
Что делают коммерческие поисковые системы?
Комбинация обоих подходов — это, по сути, то, что предлагают большинство поисковых систем. При вводе данных в поле поиска отдельные строки предлагаются в контексте других строк и терминов. Это приводит к семантическому поиску.
Для крупных поисковых провайдеров эти результаты коммерчески скорректированы и направляют пользователей к приоритетным индексам. Страницы сортируются и категоризируются с помощью правил и рекомендаций. Группы интересов определяются с помощью технологий отслеживания, алгоритмов ИИ и маркетинга баз данных, а поиск адаптируется под целевую группу.
Related Projects

LibreOffice ChatGPT Интеграция Макросов Тематическое Исследование
Исследуйте пользовательскую интеграцию макросов Python OpenAI для ChatGPT в LibreOffice, улучшая рабочие процессы с помощью ИИ непосредственно в ваших документах.

От глобального бизнеса до кухни — корпоративная медиа-ОС, которая спокойно масштабируется (stajic.de + Showcase Portals)
Глобальная стратегия работает только тогда, когда она выживает «на кухне»: ограничения, ритм, ясность и измеримый результат. Вот как Enterprise Media OS превращает рыночный шум в воспроизводимые системы — с figure.rocks и loving.rocks в качестве примеров реализации.
Web Presence Making a Statement - Automobile Bauer Joomla

Платформы присутствия — корпоративные коммуникации, которые побеждают без конкуренции
Платформа присутствия превращает операционную деятельность в ясность уровня принятия решений: контролируемые утверждения, повторяемые форматы, внутренние связи, направляющие решения, и еженедельный цикл обучения, который укрепляет доверие и пайплайн.

Производственная платформа корпоративного уровня
CMS- и портальная платформа корпоративного уровня с многобазовой архитектурой, истинной многоязычностью и профессиональной миграцией WordPress. Разработано для масштабируемых, безопасных и перспективных издательских систем.
Портал оцифровки для Архива Музея Библиотеки
Цифровой Немецкий музей посвящен цифровизации и научной обработке фондов собрания объектов, архива, а также библиотеки Немецкого музея.

От видения к ценности: максимизация ROI в POS через создание последовательного CI и стратегический брендинг
В современном ритейле преодоление разрыва между творческим видением и финансовой ценностью требует согласования корпоративной идентичности (CI) с точками продаж (POS). В данном кейсе рассматривается методология устранения когнитивных барьеров для повышения ROI.
От глобального бизнеса до кухни — система обратной коммуникации, которая по-прежнему масштабируется
Перестаньте масштабироваться на основе шума. Начните с глобальных сигналов, сведите их к нескольким устойчивым истинам и превратите их в еженедельные шаблоны, чек-листы и повторяемые “меню”, которые приносят реальную ценность.
SEO Мобильное Веб-приложение Мюнхен
SEO для мобильных веб-приложений в Мюнхене: чистая индексация, аналитика, структурированные карты сайта и оптимизация для Google News как прочный фундамент для устойчивой видимости.

Локальные корни, глобальный охват — коммуникационные и медиасистемы для современного бизнеса
Я помогаю локальному бизнесу выглядеть как мировые бренды: четкое позиционирование, высокоэффективный контент и дистрибуция, которая превращает внимание в лидов.

Разработка мобильных приложений с Apache Cordova: Кроссплатформенный кейс-стади
Изучите, как Apache Cordova превращает веб-приложения в кроссплатформенные мобильные решения для Android, iOS и других платформ, с подробным описанием процесса, стека технологий и преимуществ.