Solr Fuzzy Suggester and Solr Infix Suggester over Ajax
Project Description
For efficient searching on a website, it is important that users quickly and easily find the appropriate results. Solr Fuzzy Suggester and Solr Infix Suggester offer an efficient solution for this. They can be called and filtered via Ajax queries.
The suggester is activated via the XML component SuggestComponent in the solrconfig.xml file, as shown in the following code example:
<searchComponent name="suggest" class="solr.SuggestComponent">
<lst name="suggester">
<str name="name">mySuggester</str>
<str name="lookupImpl">FuzzyLookupFactory</str>
<str name="dictionaryImpl">DocumentDictionaryFactory</str>
<str name="field">suggest_field</str>
<str name="weightField">weight</str>
<str name="suggestAnalyzerFieldType">text_general</str>
<str name="buildOnStartup">true</str>
</lst>
</searchComponent>By using Solr Fuzzy Suggester and Solr Infix Suggester, users can quickly and easily get relevant results, as they receive suggestions and auto-completion features. Query results can then be filtered to ensure that only the most relevant results are displayed.
By implementing these technologies, websites can offer improved search functionality and a better user experience.
Configuration Example (Syntax Highlighter)
<searchComponent name="suggest" class="solr.SuggestComponent">
<lst name="suggester">
<str name="name">mySuggester</str>
<str name="lookupImpl">FuzzyLookupFactory</str>
<str name="dictionaryImpl">DocumentDictionaryFactory</str>
<str name="field">cat</str>
<str name="weightField">price</str>
<str name="suggestAnalyzerFieldType">string</str>
<str name="buildOnStartup">false</str>
</lst>
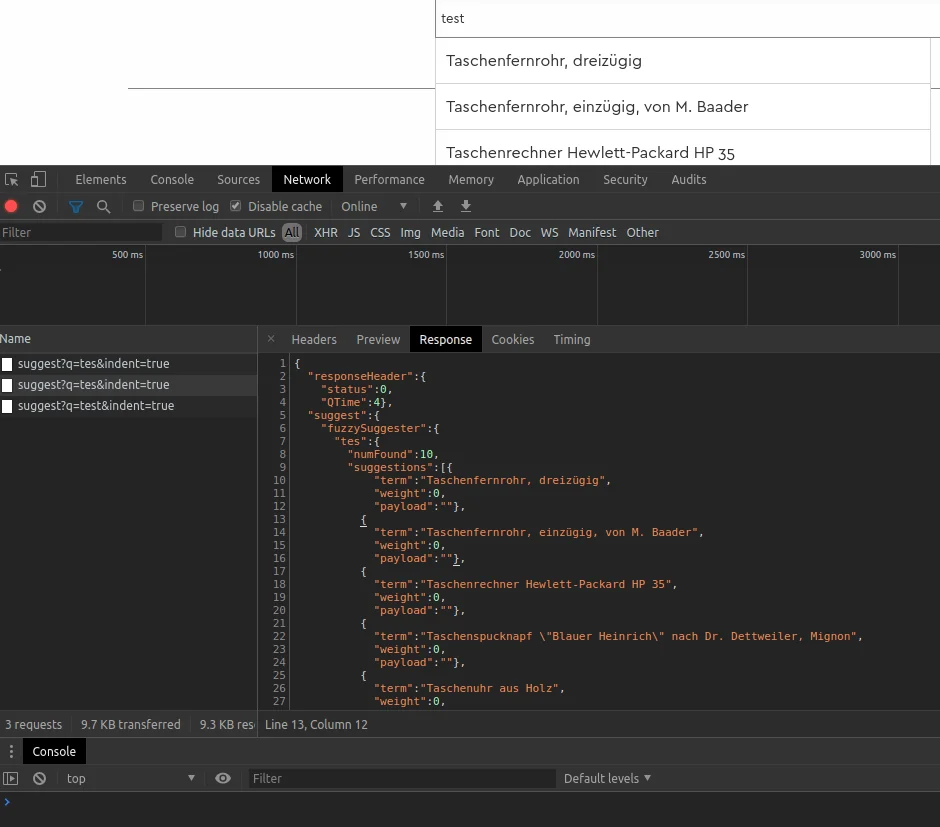
</searchComponent>The image shows what the suggester does: the input does not yield an exact match, and the Solr Suggester returns similar suggestions. There are several ways to determine string similarity. I will mention two here.
1) Fuzzy (Levenshtein distance)
The first possibility is fuzzy, which is based on the Levenshtein distance algorithm.
In JavaScript, it would look like this:
function levenshtein(a, b) {
var t = [], u, i, j, m = a.length, n = b.length;
if (!m) { return n; }
if (!n) { return m; }
for (j = 0; j <= n; j++) { t[j] = j; }
for (i = 1; i <= m; i++) {
for (u = [i], j = 1; j <= n; j++) {
u[j] = a[i - 1] === b[j - 1] ? t[j - 1] : Math.min(t[j - 1], t[j], u[j - 1]) + 1;
} t = u;
} return u[n];
}
// a and b are strings2) Infix (prefix matching and Lucene index)
The second possibility is infix, which is based on prefix matching with tokens in the indexed text. It uses the Lucene index for its dictionary. Lucene is a full-text search library (Apache Software Foundation) that contains open-source programming libraries.
In practice, it is an indexed structure that creates tokens during processing. Spaces can mark the end or beginning of a string. Individual strings are normalized for better matches — for example, converting uppercase letters to lowercase — and multiple related variants from the dictionary are also indexed.
The advantage lies in the options that can be defined in the query, which provides greater flexibility.
What do commercial search engines do?
A combination of both approaches is essentially what most search engines offer. When entering input into the search field, individual strings are suggested in the context of other strings and terms. This results in semantic search.
For large search providers, these results are commercially adjusted and direct users towards priority indices. Pages are sorted and categorized via rules and guidelines. Interest groups are determined via tracking technologies, AI algorithms, and database marketing, and the search is tailored to the target group.
Related Projects

Mobile App Creation with Apache Cordova: Cross-Platform Case Study
Explore how Apache Cordova transforms web apps into cross-platform mobile solutions for Android, iOS, and more, with detailed process, tech stack, and benefits.

LibreOffice ChatGPT Macro Integration Case Study
Explore the custom Python OpenAI macro integration for ChatGPT in LibreOffice, enhancing workflows with AI assistance directly in your documents.
From Global Business to the Kitchen — A Reverse Communication System That Still Scales
Stop scaling by noise. Start with global signals, reduce them to a few stable truths, and turn them into weekly templates, checklists, and repeatable “menus” that ship real value.

Presence Platforms — Enterprise Communication That Wins Without Competing
A Presence Platform turns operations into decision-grade clarity: governed claims, repeatable formats, internal linking that routes decisions, and a weekly learning loop that compounds trust and pipeline.
SEO Mobile Web Application Munich
SEO for Mobile Web Applications in Munich: clean indexing, analytics, structured sitemaps and Google News optimization as a solid foundation for sustainable visibility.

Local Roots, Global Reach: Implementing the Enterprise Business OS
A deep dive into transforming local business operations through the Enterprise Business OS, focusing on clear positioning, high-output content engines, and strategic distribution systems.
Web Presence Making a Statement - Automobile Bauer Joomla

From Vision to Value: Maximizing POS ROI Through Consistent CI Creation and Strategic Branding
In modern retail, bridging the gap from creative vision to financial value requires aligning Corporate Identity (CI) with the Point of Sale (POS). This case study explores the framework for eliminating cognitive friction to enhance ROI.
Digitalization portal for Archive Museum Library
The Deutsche Museum Digital is dedicated to the digitalization and scientific exploration of the collections of objects, archives, and library of the Deutsches Museum.

From Global Business to the Kitchen — Enterprise Media OS That Scales Calmly (stajic.de + Showcase Portals)
Global strategy only works if it survives the kitchen: constraints, cadence, clarity, and measurable output. Here’s how an Enterprise Media OS turns market noise into repeatable systems — with figure.rocks and loving.rocks as showcase implementations.

Enterprise-Grade Production Platform
Enterprise-grade CMS- und Portal-Plattform mit Multi-Database-Architektur, echter Mehrsprachigkeit und professioneller WordPress-Migration. Entwickelt für skalierbare, sichere und zukunftsfähige Publishing-Systeme.