规范化架构、URL 设计、解析器逻辑、API 与可扩展性规范
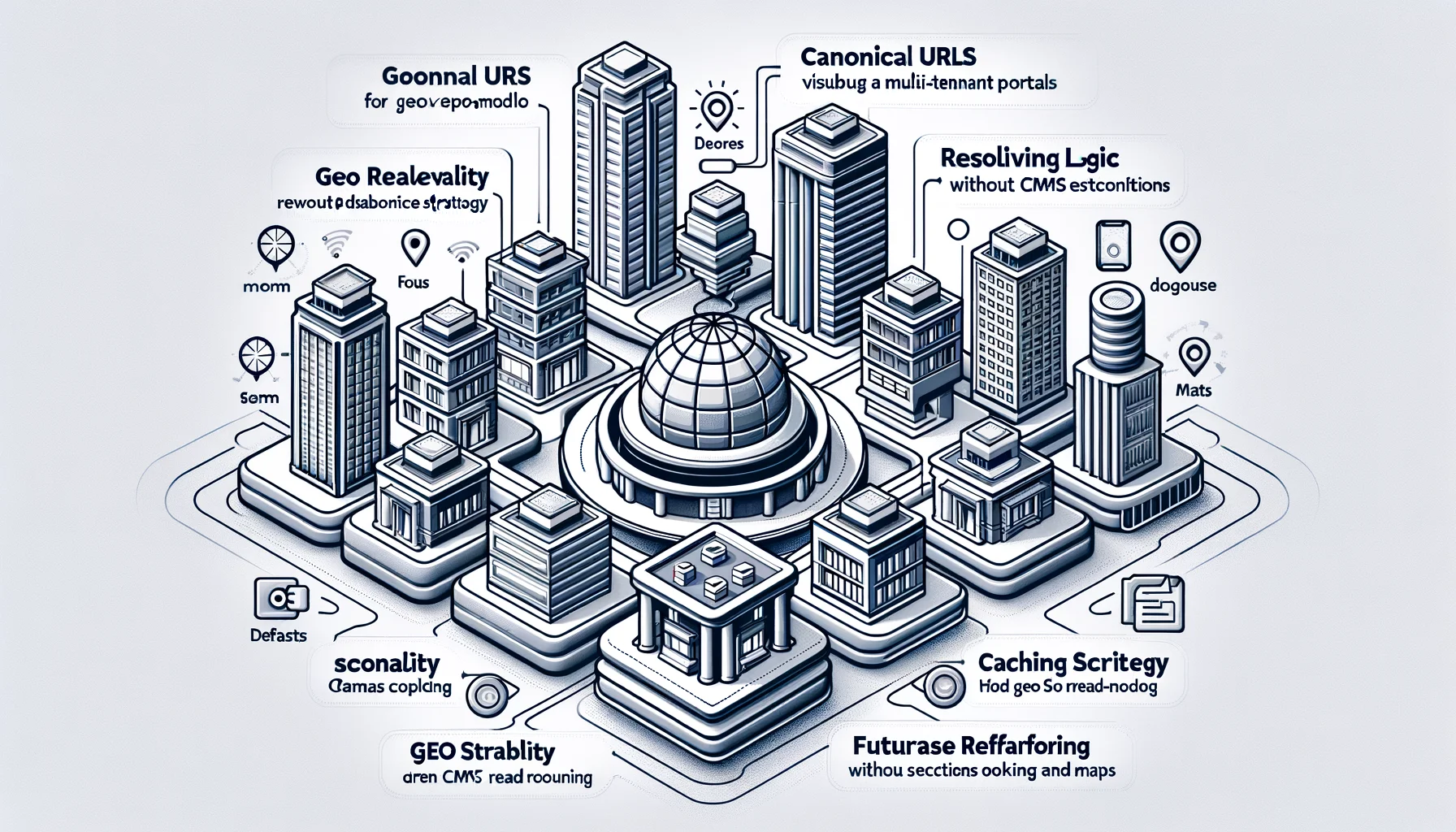
地理发现:规范架构、URL设计、解析器逻辑、API与可扩展性规范
本文档规定了跨多个门户(多租户)的基于地理的发现界面(国家/城市/半径),无需强制立即进行数据库重构,也不与CMS路由(页面/文章)耦合。它保持SEO稳定,对缓存友好,并为预订/评论/地图功能留出空间,而不会将应用变成一个臃肿的整体。
约束与非目标
- 多租户:同一代码库服务于多个门户。租户影响内容范围、品牌,有时还影响数据源。
- 地理发现必须支持:国家、城市、半径搜索(围绕一个点)。
- 无需立即进行数据库重构:我们现在无法将现有表重塑为完美的地理模式。
- 独立于CMS路由:地理页面不是“文章”或“页面”。它们不能被CMS slug冲突所阻止。
- SEO稳定性:规范URL在过滤器/排序选项更改时不得改变。
- 缓存友好性:CDN + 服务器缓存应具有可预测的键。避免每个用户的变体。
- 严格关注点分离:发现、CMS和租户解析是独立的模块,具有明确的边界。
- 非目标(目前):完美的地理编码。我们接受一个地理编码器,一种标准化策略,并存储标准化结果。
规范架构
我们将地理发现实现为其自身的有界上下文,具有较小的公共接口:(1) URL -> 解析器,(2) 解析器 -> 查询计划,(3) 查询计划 -> 数据提供者,(4) 响应 -> SEO + 缓存元数据。CMS路由从不调用发现模块。发现模块从不调用CMS路由。它们仅共享低级实用程序(HTTP、缓存、租户上下文)。
关键组件
- TenantContext:根据主机头(或内部调用中的显式门户ID)解析租户。
- GeoResolver:解析 + 验证地理URL段;发出标准化的GeoQuery。
- GeoIndex(读取模型):一个单独的表/集合,映射entityId -> 纬度/经度 + 租户范围 + 最小可搜索字段。这避免了重构源数据库表。
- 数据提供者:可插拔的源(例如,现有的SQL表、WordPress API、另一个门户服务)。它们位于接口之后。
- SEO路由器:生成规范URL和元数据(规范、hreflang(如果需要)、robots标志)。
- 缓存层:CDN缓存键 + 具有租户范围键和版本控制的服务器端缓存。
文件夹结构
apps/
web/
routes/
discovery/ # 发现入口点(非CMS)
pages/
[...cms].vue # CMS 通配符(远离 /discover)
server/
src/
tenant/
TenantContext.ts
tenantConfig.ts
discovery/
geo/
GeoResolver.ts
GeoQuery.ts
GeoCanonical.ts
GeoController.ts
providers/
GeoProvider.ts
SqlGeoProvider.ts
RemoteGeoProvider.ts
index/
GeoIndexRepository.ts
migrations/
cache/
Cache.ts
cacheKeys.ts
http/
errors.ts
requestContext.ts
packages/
shared/
src/
geo/
normalize.ts
haversine.ts
validation/
zod.ts
URL设计(SEO规范)
我们保持规范URL纯粹是层次化的且易于人类阅读。过滤器/排序保留在查询字符串中,但不会影响规范。半径搜索使用一个稳定的“near”页面,其规范基于一个四舍五入的坐标单元,而不是原始的纬度/经度。这防止了无限的URL变体。它也防止了缓存爆炸。这是一个有意的折衷。
- 国家着陆页:/discover/{countryCode}(示例:/discover/de)
- 城市着陆页:/discover/{countryCode}/{citySlug}(示例:/discover/de/munich)
- 附近(半径):/discover/{countryCode}/near/{cellId}(示例:/discover/de/near/u281z),其中cellId是一个短的地理哈希标识符
- 可选查询参数(非规范):?q=shih-tzu&category=pet-care&sort=rating&page=2
- 租户不在路径中。租户是主机(portal-a.tld, portal-b.tld)。内部调用传递x-tenant-id。
规范规则
- 国家/城市页面规范化为其自身的干净路径(无查询字符串)。
- 附近页面规范化为 /discover/{country}/near/{cellId}。规范源自一个四舍五入的单元,而不是传入的坐标。
- page=1 从规范和内部链接生成中省略。
- 不支持的组合(例如,国家不匹配)返回404,而不是重定向。重定向链在测试中损害了爬取预算。
解析器逻辑
解析器输入是(租户,路径名,查询)。解析器输出是一个带有查询计划的标准化的GeoQuery。解析器内部没有数据库访问。这种分离后来很重要。它使我们避免了一个棘手的缓存错误。
export type TenantId = string;
export type GeoScope =
| { kind: 'country'; countryCode: string }
| { kind: 'city'; countryCode: string; citySlug: string }
| { kind: 'near'; countryCode: string; cellId: string; radiusMeters: number };
export type GeoFilters = {
q?: string;
category?: string;
sort?: 'relevance' | 'rating' | 'distance';
page: number;
pageSize: number;
};
export type GeoQuery = {
tenantId: TenantId;
scope: GeoScope;
filters: GeoFilters;
canonicalPath: string;
cacheKey: string;
};
import { z } from 'zod';
import type { GeoQuery, TenantId } from './GeoQuery';
const QuerySchema = z.object({
q: z.string().trim().min(1).max(120).optional(),
category: z.string().trim().min(1).max(60).optional(),
sort: z.enum(['relevance', 'rating', 'distance']).optional(),
page: z.coerce.number().int().min(1).max(200).default(1),
pageSize: z.coerce.number().int().min(5).max(50).default(20)
});
const CountryCodeSchema = z.string().regex(/^[a-z]{2}$/i);
const CitySlugSchema = z.string().regex(/^[a-z0-9-]{2,80}$/i);
const CellIdSchema = z.string().regex(/^[a-z0-9]{4,12}$/i);
export function resolveGeo(
tenantId: TenantId,
pathname: string,
query: Record<string, unknown>
): GeoQuery {
const filters = QuerySchema.parse(query);
const parts = pathname.split('/').filter(Boolean);
// /discover/{country}
// /discover/{country}/{city}
// /discover/{country}/near/{cellId}
if (parts[0] !== 'discover') {
throw new Error('Not a discovery route');
}
const countryCode = CountryCodeSchema.parse(parts[1] ?? '');
let scope: GeoQuery['scope'];
if (parts.length === 2) {
scope = { kind: 'country', countryCode: countryCode.toLowerCase() };
} else if (parts[2] === 'near') {
const cellId = CellIdSchema.parse(parts[3] ?? '');
// 半径不在路径中,但有边界。
const radiusMeters = Math.min(50000, Math.max(500, Number(query['r'] ?? 5000)));
scope = { kind: 'near', countryCode: countryCode.toLowerCase(), cellId, radiusMeters };
} else {
const citySlug = CitySlugSchema.parse(parts[2] ?? '');
scope = { kind: 'city', countryCode: countryCode.toLowerCase(), citySlug: citySlug.toLowerCase() };
}
const canonicalPath = canonicalizePath(scope);
const cacheKey = buildCacheKey(tenantId, scope, filters);
return {
tenantId,
scope,
filters: {
...filters,
sort: filters.sort ?? 'relevance'
},
canonicalPath,
cacheKey
};
}
function canonicalizePath(scope: GeoQuery['scope']): string {
switch (scope.kind) {
case 'country':
return `/discover/${scope.countryCode}`;
case 'city':
return `/discover/${scope.countryCode}/${scope.citySlug}`;
case 'near':
return `/discover/${scope.countryCode}/near/${scope.cellId}`;
}
}
function buildCacheKey(
tenantId: string,
scope: GeoQuery['scope'],
filters: { q?: string; category?: string; sort?: string; page: number; pageSize: number }
): string {
// 注意:规范忽略查询字符串,但缓存不忽略。
// 但我们保持其有界且明确。
const q = filters.q ? `q=${filters.q}` : '';
const c = filters.category ? `cat=${filters.category}` : '';
const s = `sort=${filters.sort ?? 'relevance'}`;
const p = `p=${filters.page}`;
const ps = `ps=${filters.pageSize}`;
const scopeKey =
scope.kind === 'country'
? `country:${scope.countryCode}`
: scope.kind === 'city'
? `city:${scope.countryCode}:${scope.citySlug}`
: `near:${scope.countryCode}:${scope.cellId}:r${scope.radiusMeters}`;
return `geo:v1:tenant=${tenantId}:${scopeKey}:${[q, c, s, p, ps].filter(Boolean).join('&')}`;
}
逐步请求流程
- 边缘/CDN接收请求。缓存键包括主机 + 路径 + 有界查询参数(q, category, sort, page, pageSize, r)。
- 应用服务器根据主机头创建TenantContext。尚未访问数据库。
- GeoResolver解析URL。生成带有canonicalPath和server cacheKey的GeoQuery。
- GeoController构建一个QueryPlan。它根据租户配置和范围类型决定要调用哪个提供者。
- 提供者针对GeoIndex(快速)执行读取模型查询。然后使用实体ID从现有的源数据库/API水合结果(无需重构)。
- 响应组装器附加SEO元数据:规范、robots、分页链接。
- 服务器设置缓存头(s-maxage + stale-while-revalidate)。正文是租户范围的,从不跨租户共享。
无重构策略:GeoIndex读取模型
我们现在无法重构现有的内容表。因此,我们添加一个单独的GeoIndex,可以独立重建。它只存储足够的信息以高效地进行发现:tenantId, entityId, entityType, countryCode, citySlug, lat, lng,以及一些过滤字段。水合操作从当前源(SQL行、CMS API等)获取完整对象。
权衡:最终一致性。索引重建延迟对于发现页面是可接受的。我们设置SLA:更新在15分钟内出现。如果我们以后需要实时性(预订可用性),那是一个不同的界面,不应重用发现缓存。
API接口
两个接口:(A) 用于SEO和用户的HTML页面,(B) 用于客户端渲染和未来扩展的JSON API。相同的解析器 + 相同的查询计划。不同的呈现器。
- HTML:GET /discover/{country}, /discover/{country}/{city}, /discover/{country}/near/{cellId}
- API:GET /api/discovery?scope=country|city|near&country=..&city=..&cell=..&r=..&q=..&category=..&sort=..&page=..
- 管理(内部):POST /internal/geoindex/rebuild(受保护),POST /internal/geoindex/upsert(可选,以后)
import type { IncomingMessage, ServerResponse } from 'http';
import { resolveGeo } from './GeoResolver';
import { runQueryPlan } from './GeoController';
export async function discoveryApi(req: IncomingMessage, res: ServerResponse) {
const url = new URL(req.url ?? '', 'http://localhost');
const tenantId = String(req.headers['x-tenant-id'] ?? 'default');
// 我们通过映射查询 -> 伪路径来重用相同的解析器。
// 这保持了HTML和API之间的逻辑一致。
const scope = url.searchParams.get('scope') ?? 'country';
const country = url.searchParams.get('country') ?? '';
const city = url.searchParams.get('city');
const cell = url.searchParams.get('cell');
const pseudoPath =
scope === 'city' && city
? `/discover/${country}/${city}`
: scope === 'near' && cell
? `/discover/${country}/near/${cell}`
: `/discover/${country}`;
const geoQuery = resolveGeo(tenantId, pseudoPath, Object.fromEntries(url.searchParams.entries()));
const result = await runQueryPlan(geoQuery);
res.statusCode = 200;
res.setHeader('content-type', 'application/json; charset=utf-8');
// 缓存:在CDN公开,租户特定的键已在上游处理
res.setHeader('cache-control', 'public, s-maxage=300, stale-while-revalidate=600');
res.end(JSON.stringify(result));
}
可扩展性与性能
- 主要性能目标:从CDN为流行的地理着陆页(国家/城市)提供缓存的发现HTML。
- 附近页面可缓存,但有更多变体(cellId + r + q + category + sort + page)。我们限制r、pageSize,并严格验证过滤器。
- GeoIndex查询必须快速:使用tenantId + countryCode + citySlug索引;对于附近搜索,使用单元桶(前缀匹配),然后在应用中进行距离细化。
- 避免在大数据集上进行昂贵的SQL半正矢计算。它看起来简单。其实不然。
- 水合操作按entityId列表批量进行。每个entityType一个查询,而不是N+1。
半径搜索策略(附近页面)
我们不对所有行进行完整的半径扫描。而是:(1) cellId映射到一个边界桶(类似地理哈希的前缀),(2) 通过桶前缀从GeoIndex获取候选,(3) 在应用中使用半正矢距离进行细化,(4) 排序 + 分页。这使数据库负载可预测。
export function haversineMeters(a: { lat: number; lng: number }, b: { lat: number; lng: number }): number {
const R = 6371000;
const toRad = (d: number) => (d * Math.PI) / 180;
const dLat = toRad(b.lat - a.lat);
const dLng = toRad(b.lng - a.lng);
const lat1 = toRad(a.lat);
const lat2 = toRad(b.lat);
const sinDLat = Math.sin(dLat / 2);
const sinDLng = Math.sin(dLng / 2);
const h = sinDLat * sinDLat + Math.cos(lat1) * Math.cos(lat2) * sinDLng * sinDLng;
const c = 2 * Math.asin(Math.min(1, Math.sqrt(h)));
return R * c;
}
缓存模型(CDN + 服务器)
我们在两个层进行缓存。CDN为匿名流量缓存完整的HTML/JSON。服务器缓存存储提供者结果,键为GeoQuery.cacheKey。该键包括租户、范围和有界过滤器。并非所有内容都应被缓存。以后的预订可用性将被排除在外。
- CDN缓存键随主机头变化。这是租户边界。
- 服务器缓存键明确包括tenantId。永远不要依赖进程内的隐式主机。
- 缓存TTL:国家/城市页面在CDN为30–60分钟(启用stale-while-revalidate)。附近页面为5分钟。
- 我们为每个租户保留一个手动清除杠杆(缓存键中的版本后缀)。在迁移和错误部署期间使用。
SEO稳定性细节
- 规范标签:始终指向干净的层次化路径(无查询字符串)。
- Robots:如果存在查询参数且不在白名单中(q/category/sort/page/pageSize/r),则设置noindex。这阻止来自外部链接的垃圾参数。
- 分页:仅当页面 > 1 且 resultCount > pageSize 时生成 rel=next/prev。
- 稳定的内部链接:UI链接始终发出规范路径;查询字符串仅用于用户选择的过滤器。
未来扩展(无臃肿)
我们通过添加提供者和呈现器来扩展,而不是通过将功能塞入解析器。预订、评论和地图挂载在实体页面或专用API上。发现仍然是一个列表和过滤界面。该边界在代码审查中强制执行。
- 预订:单独的 /api/booking 端点。发现仅显示缓存的且非个性化的可用性徽章。
- 评论:单独的评论服务/提供者。发现从GeoIndex(预计算)读取聚合的评分字段。
- 地图:地图瓦片和标记从 /api/discovery/markers 获取,具有积极的缓存;如果破坏TTFB,则不嵌入到HTML响应中。
一个出错的地方(以及我们改变了什么)
我们发布了第一个版本,其服务器缓存键没有包含tenantId。它在本地“工作”。在暂存环境中看起来很好。然后到了生产环境。门户A开始在城市的页面上显示门户B的列表。相同的路径,不同的租户。缓存冲突。很糟糕。
修复很无聊但很严格:tenantId在GeoQuery中变为强制性的,并且缓存键构建移入解析器,因此无法跳过。我们还添加了一个运行时断言:如果水合的实体包含不同的tenantId,我们抛出异常并跳过缓存写入。这是故意制造噪音的。
查询计划与提供者契约
import type { GeoQuery } from '../GeoQuery';
export type GeoHit = {
entityId: string;
entityType: 'place' | 'service' | 'listing';
lat: number;
lng: number;
citySlug?: string;
countryCode: string;
score?: number;
distanceMeters?: number;
};
export type GeoResult = {
hits: GeoHit[];
total: number;
page: number;
pageSize: number;
};
export interface GeoProvider {
search(query: GeoQuery): Promise<GeoResult>;
}
QueryPlan是一个基于(租户配置 + 范围类型)的小型开关。示例:一些租户仅使用SQL;其他租户使用远程门户服务。相同的GeoQuery输入。相同的GeoResult输出。这使得推出可预测。
SQL GeoIndex:最小模式
CREATE TABLE geo_index (
tenant_id TEXT NOT NULL,
entity_id TEXT NOT NULL,
entity_type TEXT NOT NULL,
country_code TEXT NOT NULL,
city_slug TEXT,
lat DOUBLE PRECISION NOT NULL,
lng DOUBLE PRECISION NOT NULL,
cell_prefix TEXT NOT NULL,
category TEXT,
rating_avg DOUBLE PRECISION,
updated_at TIMESTAMP NOT NULL DEFAULT NOW(),
PRIMARY KEY (tenant_id, entity_id)
);
CREATE INDEX geo_index_country_city
ON geo_index (tenant_id, country_code, city_slug);
CREATE INDEX geo_index_cell_prefix
ON geo_index (tenant_id, country_code, cell_prefix);
权衡(明确)
- 我们为了稳定的URL而牺牲了完美的精度:附近页面通过cellId规范化。两个相距300米的用户可以登陆到同一个规范页面。可以接受。
- 我们为了可缓存性而牺牲了新鲜度:发现页面不是实时的。索引更新可能延迟。
- 我们现在避免了数据库重构,但我们需要支付额外的写入路径来维护GeoIndex。
- 我们避免了与CMS路由的耦合,但我们现在拥有一个单独的路由命名空间(/discover)。这是有意的。这也是我们必须遵守的承诺。
- 我们在应用代码中进行附近搜索的距离细化,以避免昂贵的数据库计算。这将CPU转移到应用层,更容易水平扩展。
推出计划(实用)
- 在功能标志后发布解析器 + 返回404的空页面。确认路由不与CMS通配符冲突。
- 为一个租户构建GeoIndex回填作业。验证计数与源数据。预期不匹配;记录它们。
- 仅启用国家页面。观察缓存命中率和爬取统计。
- 接下来启用城市页面。然后最后启用附近页面(它们是变体生成器)。
- 在我们看到稳定的缓存键后,添加JSON API消费者(地图标记、客户端过滤)。
验收清单
- 多租户隔离:两个主机上的相同路径从不共享服务器缓存条目。
- 规范URL不包括查询参数,并且在过滤器更改时保持稳定。
- CMS slug冲突不影响 /discover 路由。
- 附近页面不会生成无限的URL排列(有界的r、pageSize)。
- 提供者契约返回确定性的分页和总计数。
- GeoIndex重建可以在没有停机的情况下运行,并且不会长时间锁定源表。
Related Articles

Quectel RM500U-EA在ZBT Z8102AX中:5G频段、o2德国及实际信号表现
ZBT Z8102AX 使用移远 RM500U-EA 调制解调器实现 4G 和 5G 连接。在首次实际测试中,该路由器成功连接至德国 o2 网络,使用 LTE Band 3 和 NR n28 频段。调制解调器工作正常,但更深层次的诊断功能如 RSRP、RSRQ、SINR、频段锁定及小区行为仍需进一步测试。
模型-视图-控制器(MVC):现代Web应用的结构支柱
模型-视图-控制器(通常简称为MVC)依然是软件开发中最经久不衰的架构模式之一。它为团队提供了一种实用的方法,将业务逻辑、展示层和用户交互分离,从而使应用程序更易于构建、扩展、测试和维护。本文阐述了MVC是什么、为何至今仍具重要性、它在当今Web技术栈中的定位,以及它如何与更广泛的平台架构、交付质量、迁移策略和运维成熟度相连接。

ZBT Z8102AX 硬件与包装评测:强劲路由器,薄弱包装
ZBT Z8102AX 作为一款纤薄黑色金属5G OpenWrt路由器,配备多个天线接口、双SIM卡槽、USB、LAN/WAN端口及实用配件套装,给人留下扎实的第一印象。硬件设计实用且专业,但包装显然是薄弱环节。
企业级多租户架构,适用于国际平台
Loving Rocks 是一款企业级婚礼平台,采用真正的多租户架构设计,实现租户间数据库隔离,并内置国际化支持,以确保全球可扩展性、安全性及长期运营稳定性。